





정보기술(IT) 시장에 관심 많으신 독자 여러분, 안녕하세요. '삼성은 AI 추론 칩 '마하 1'을 어떻게 만들까?<1편>'에서는 삼성전자가 왜 인공지능(AI) 추론 칩에서 경량화를 도입하게 됐는지를 살펴봤습니다. 그러면서 마하1의 데이터 압축 방법 중 하나인 가지치기(Pruning) 콘셉트도 들여다봤죠. 마하1에 대한 핵심을 요약하면 △엔비디아 B200 GPU의 아성에 도전하는 NPU 기반의 단독 AI 칩 △압축 알고리즘으로 승부수를 띄워 HBM 대신 LPDDR D램을 결합하는 칩입니다.
2편에서는 또다른 압축 방법인 양자화(Quantization)와 세번째 키워드인 LPDDR D램·마하 1에 대해 업데이트된 소식 등을 다뤄보려고 합니다. 우선 양자화부터 짚고 넘어가겠습니다.

②압축-2: 양자화(Quantization)
양자화가 무엇일까. 네이버 지식백과를 찾아봤더니 '단절없이 연속된 변화량을 일정한 폭 ∆로 불연속적으로 변화하는 유한 개의 단계로 구분하고, 각 단계에 대하여 각각 유니크한 값을 부여하는 것'이라고 설명합니다.

쉽지 않죠. 그래도 우리는 기술을 너무 좋아하는 사람들이니까 저와 함께 기술 산을 넘어봅시다. 이 콘셉트를 아주 쉽게 표현하면요. '의류 압축팩' 같은 겁니다. 우리가 겨울에 입는 롱패딩을 보관하려면 부피가 너무 크죠. 그래서 압축팩에 넣은 다음 공기를 빨아들여 부피를 최대한 줄인 뒤 옷장에 넣어두는데요. 양자화도 비슷한 개념입니다. 이제 한 발짝만 더 들어가봅시다.
숫자의 세계는 무한하죠. 그런데 디지털 연산 장치 세계에서는요. 우리가 현실에서 많이 쓰는 10진법의 수를 2진법으로 바꿔서 이 데이터를 연산에 활용하거나 저장해 놓습니다.
+(양수)와 -(음수) 부호는 물론 소수점 아래까지도 일정한 규칙에 의해 이진법 형태로 바꿀 수 있습니다. 부호·지수·분수로 나눠서 수를 표현하죠. 소수점의 위치가 고정되지 않고 지수에 따라 떠다니듯 움직인다고 해서 ‘부동소수점(Floating Point)’이란 용어도 씁니다.
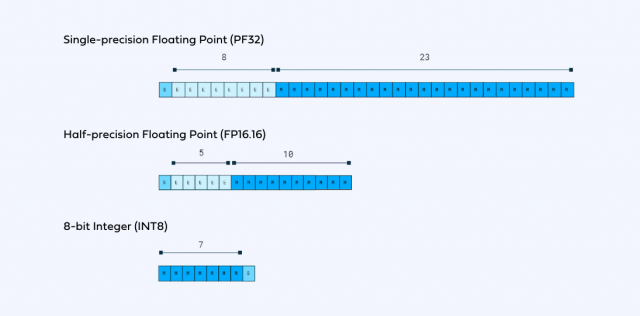
가장 좋은 예로 10진법의 숫자를 32개의 0 또는 1로 나타낼 수 있습니다. 실수(實數·real number) 기준 -3.40X38승부터 3.40X10의 38승 사이의 약 40억개의 수를 32비트로 표현할 수 있다고 하죠. 업계에서는 이 방법을 ‘FP(Floating Point)32’라고 부릅니다.
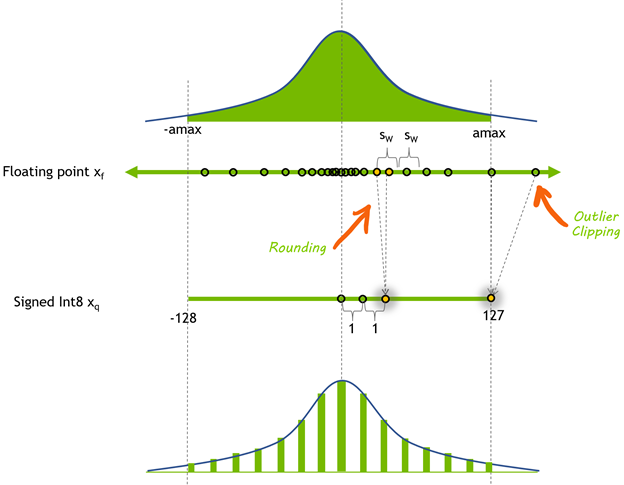
그런데 이걸 압축할 수도 있습니다. 32비트로 나타낼 수 있었던 소수점 달린 실수를요. 특정한 정수(整數·integer)로 만들어 버립니다. 예컨대 어떤 실수를 8비트까지 표현할 수 있는 정수로 바꾸는 건데요. -128(10000000)부터 127(11111111)까지, 부호를 쓰지 않는다면 0(00000000)부터 255(11111111)까지 8비트로 나타낼 수 있는 256개 각각의 정수에 수십 억개 실수를 분류해서 포함시킨 뒤 “넌 이제 이 숫자야”라고 ‘퉁치는’ 겁니다. 그렇게 32비트 데이터가 8비트로 압축됩니다. FP32로 표현한 수가 INT(integer)8 표현한 수로 변환되는 겁니다.
이제 양자화 압축 방법에 대해 조금 감을 잡으셨나요. 정말 간단히 압축하면 32비트로 나타낸 실수를 8비트로 압축하기 위해 정수로 만드는 겁니다.
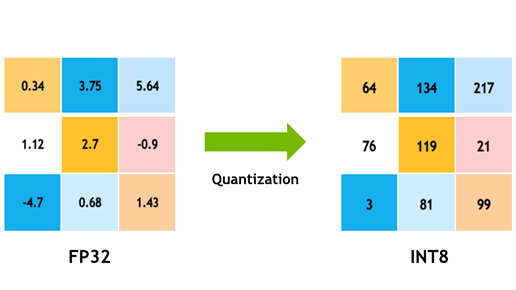
이렇게 하면 장점이 많죠. 그야말로 데이터가 경량화됩니다. 메모리 안에 저장되는 파라미터(매개 변수)가 홀쭉해지니까 더 많은 데이터를 저장할 수 있고요. 병목현상이 일어나는 AI 칩과 메모리 사이의 터널에서는 같은 시간에도 훨씬 많은 데이터들이 왕복할 수 있겠죠.
그럼 이 양자화 기술을 마하1에 어떻게 도입하는 것일까. 네이버에서 지난해 냈던 논문으로 추정해보면 삼성전자는 네이버와 협력해서 연산에 필요한 32비트 파라미터를 8분의 1로 줄인 4비트 아래로 양자화시키는 알고리즘을 연구할 가능성이 큽니다. 수십 억개의 숫자를 0~15 또는 -8과 7 사이 정수, 즉 4비트로 나타낼 수 있는 단 16개 숫자 안으로 묶는거죠.
특히 AI 연산에서 중요한 정보에 가중치를 두는 파라미터(Weights)만 대폭 압축하겠다는 콘셉트를 잡고요. 양자화 작업이 까다로운 활성화(Activation) 함수 쪽에서는 이 알고리즘을 도입하지 않는 것으로 알려졌습니다. 아울러 가중치의 압축이 유지된 상태에서도 연산을 할 수 있는 신박한 NPU 회로를 개발해 양자화로 벌어질 수 있는 지연 현상을 최소화할 것으로 보입니다.
물론 양자화의 큰 단점도 있죠. 비트를 8분의 1로 경량화했으니 연산 결과값의 정확도가 그만큼 떨어질 것이라는 지적에 직면할 수밖에 없습니다. 이 문제를 해결하기 위한 솔루션을 추정해보면요. 네이버는 논문을 통해 이른바 'PEQA'라는 기술을 소개한 적 있습니다.
양자화를 한 가중치 꾸러미에서 특정한 열에만 수를 곱하는 이른바 ‘파인 튜닝’ 기술로 요약됩니다. 꼭 필요하고 중요한 가중치에 '가중치'를 더 줘서 경량화와 함께 정확도까지 챙기겠다는 의미죠.
결론적으로 마하 1에는 1편에서 소개해드렸던 가지치기(Pruning)와 양자화를 중심으로 만든 압축 알고리즘이 큰 경쟁력이 될 것으로 예상됩니다. 물론 엔비디아·인텔·AMD 등 세계 최고의 AI 업체들도 이런 압축 알고리즘을 고려하고 있을 겁니다.
다만 삼성전자와 네이버가 공동개발하는 마하1에 기대를 걸어볼만 한 것은요. 양산된 GPU나 AI 반도체의 하드웨어 조건에 억지로 끼워맞춘 기성 경량화 알고리즘이 아니라, 경량화의 힘을 믿고 중점 개발한 압축 알고리즘에 최적화한 AI 칩을 설계하고 있다는 것입니다. 엔비디아 GPU와 마하1의 차별점이 바로 이 부분인데요. 과연 내년에 괄목할 만한 성과가 나올지 지켜봐야겠습니다.
③LPDDR

이렇게 파라미터 압축이 성공적으로 이뤄지면 무엇이 가장 좋을까요. 우리는 1편에서 봤던 첫 번째 문제로 다시 돌아갑니다. 전력을 아낄 수 있습니다.
삼성전자 설명대로 여러 압축 기술을 이용해 메모리 병목현상을 8분의 1 이상 줄인다면 HBM이 필요하지 않을 수 있습니다. 데이터 출입구(I/O)의 수가 1024개가 아니더라도 가벼워진 데이터들이 교통체증 없이 AI 칩과 메모리 사이를 원활하게 이동할 수 있다는 거죠.
그러니까 HBM을 대신해 기존 DDR D램도 아니고 저전력(Low Power·LP)DDR D램까지 쓸 수 있습니다. LPDDR D램은 핀 수가 현존 HBM의 16분의 1 수준인 64개입니다. 마하1은 파격적인 경량화를 했으니 AI 추론이 무리없이 가능하고, LPDDR D램 효과로 전력 효율도 8배나 좋다고 합니다.
게다가 LPDDR D램은 HBM보다 판매 가격이 6~7배나 저렴하죠. 계획대로만 된다면 전력으로 보나 구입 비용으로 보나 마하1이 범용 AI GPU보다 효율이 좋은 것 같습니다.
3월 20일 삼성전자가 마하1에 대해 발표한 이후 한달간 업데이트된 내용을 정리하면 이렇습니다.
⑴ 마하1의 고객사는 네이버인 것으로 확인됩니다. 마하1은 서버용 칩입니다. 네이버는 자사 데이터 센터에 엔비디아 GPU-인텔의 가우디 칩-마하1으로 AI 칩 파트너를 다변화하는 파격적 실험에 돌입한 것으로 보입니다.
⑵마하1은 5나노 이하 파운드리를 활용합니다. NPU가 핵심 코어인 제품입니다. 네이버를 위한 시제품이 올해 말에 나올 수 있으나 본격 양산은 시간이 더 필요하다는 의견이 많습니다.
⑶경계현 삼성전자 사장도 시사했듯이 시스템LSI사업부 안에서는 마하2 개발에 들어간 것으로 파악됩니다.
사실 독자님들도 마하1에 대해 다양한 우려를 가지고 계실 것입니다. △엑시노스도 성능이 별로라고 하던데 AI 추론 칩이라고 엔비디아를 넘을 수 있을까 △아직 결과물도 없는데 확신을 가질 수는 없지 않은가.
그럼에도 우리나라 최고의 자본력과 기술을 가진 반도체·IT 회사가 힘을 합친 만큼 말이죠. 결과물이 나올 때까지는 우려와 비판보다 기대의 시각으로 기다려 보는 것은 어떨까 싶습니다. 어쩌면 우리나라 시스템 반도체 도약의 속도가 '마하' 단위로 빨라질 모멘텀이 될 수도 있으니까요. 오늘은 여기까집니다. 즐거운 화요일 되세요.

< 저작권자 ⓒ 서울경제, 무단 전재 및 재배포 금지 >






































